
So you are a good marketing guy & is currently running a lot of A/B tests. But do you know when to actually declare a test as “done”?
- It is not when you reach 100 conversions.
- It is not when you reach 90% statistical significance.
- It is certainly not whenever the testing tool hits ok.
All the above are common misconceptions.
Let’s take a look at them one by one, and figure out the truth.
Get the sample size, Forget Magic Numbers.
The first step to becoming a good optimizer is not depending on miracles to get your optimization done.
Running a test until it hits a certain number of conversions per variation is as good as a miracle. There should be math & not magic.
Calculating the needed sample size before you start the test & not having a specific number of conversions as a goal is an answer.
You can use one of the online sample size calculators like this or this. Our favorite tool is Evan Miller’s tool. Here’s what you will do with it:
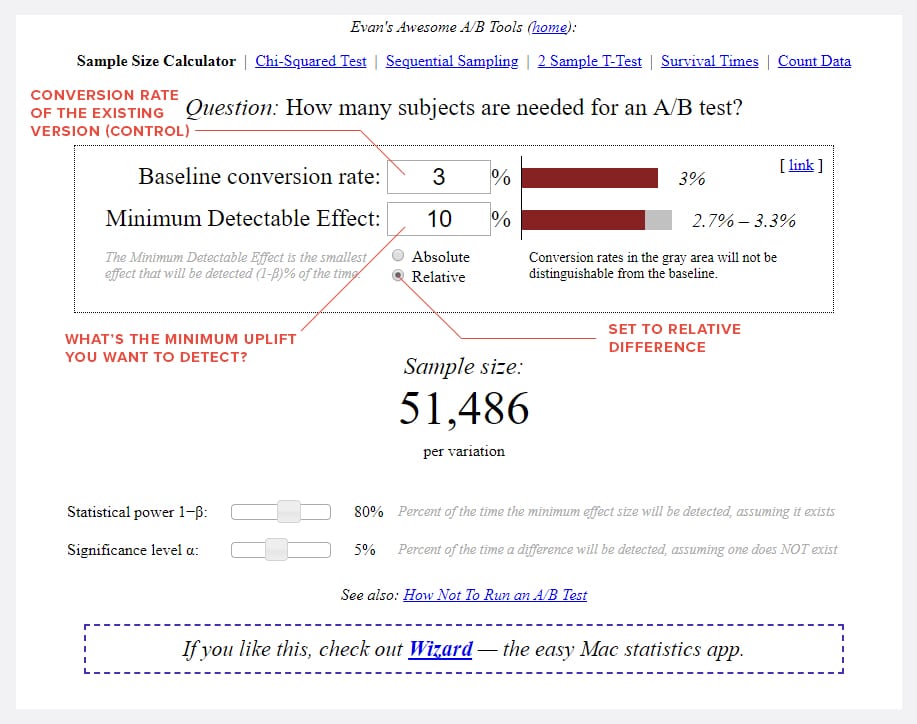
This tool tells you the number of unique visitors per variation you need before having enough sample size to base your conclusions on.
The higher the minimum detectable effect, the smaller the sample size you need and vice versa.
What if you want to be able to detect at least a 20% uplift, but the uplift is only at 8% when you reach the pre-calculated sample size?
That means you don’t actually have enough evidence to know one way or another.
Hence, the experiment is inconclusive.
What is an ideal sample size?
Small websites who have less than 1,000 conversions (e.g. quote requests, transactions, consultation requests, etc..) per month may not even be ready for A/B testing because the sample size is not enough.
You could perhaps run one A/B test per month provided that the uplift is big enough to tell the difference.
Assume a website that does 450 conversions & has a 3% conversion rate.
This means we get 15,000 visits per month.
Let’s say we are being optimistic, we want to run an A/B test and expect a 20% lift.
Here is the sample size we get when we use our favorite sample size calculator Optimizely:
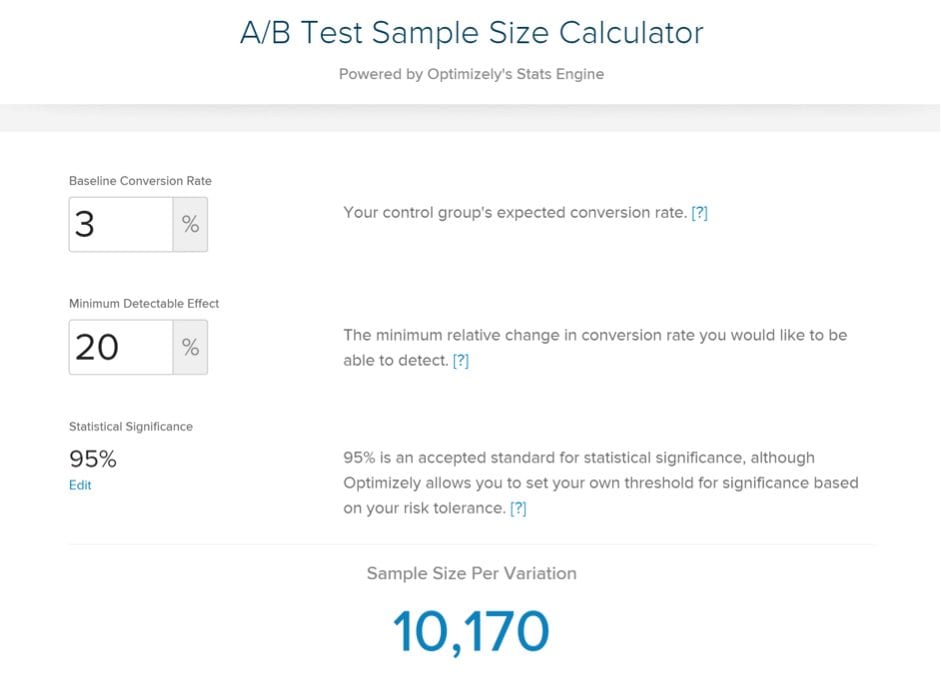
In order to run an A/B test, we’d need to get 10,170 x 2 = 20,340 visitors that month.
Hence the test couldn’t be run in one-month because there is not enough traffic.
Running a test for too long results in sample pollution, mainly cookie pollution, because most cookies expire in a certain timeframe. If the same user returns to your website again with an expired cookie, your analytics tool will treat it as another user, which causes inconsistency in your results and those results can’t be trusted.
Because there is not enough traffic for a 20% uplift and risk of inconsistency in the results because of the tests being run for longer periods it’s better to go for a bigger uplift than 20%.
What actually works well can’t be determined. But the chances of identifying an accurate uplift would go up exponentially with a data-driven test hypothesis.
Another thing – if you want to look at the A/B test results across segments (e.g. how the test did across different devices, browsers or traffic sources), then you need enough sample size PER SEGMENT before you can even look at the outcome.
A representative sample is needed
Calculating sample size alone is not enough.
The test sample should have enough people and they should represent all of your incoming traffic.
This means your sample has to include every day of the week, every traffic source, newsletter & other things that may affect the behavior of your target audience.
The rule of the thumb is that you should run the test for at least 2 business cycles.
That’s 2 to 4 weeks for most businesses.
Looking at the statistical significance
The statistical significance (p-value) is just the probability of seeing a result given that the null hypothesis (conclude that two groups having no relation with each other) is true.
It doesn’t tell if the probability of B scenario happening is higher than A scenario.
Neither does it tell that we might make a mistake in selecting B over A.
Both of them are common misconceptions.
Before having enough sample size & enough representativeness in the sample, a statistical significance percentage is a meaningless number for our purposes.
Ignore it until the 2 previous conditions have been met.
Just because your test hits 95% significance level or higher, you shouldn’t stop or validate the test. Only conclude the test results once the sample size is reached.
Again, statistical significance does not equate to the validity of the A/B test.
Pay attention to error margins
The testing tools, e.g. KISSmetrics, Maxymiser, Unbounce, would tell you the conversion rate for each variation but those numbers are not completely accurate.
All these figures are just median points – just the ranges of possibilities and the range get smaller with time and your sample size increases.
It’s not like A converts at 14.6% and B converts at 16.4% precisely – the tools will also tell you what the margin of error is.
If the error margin is ±2% then it’s also possible that A converts at 13.6% and B converts at 18.4%. Or A might be 16.6% and B 14.4%.
So, the conversion range can be described as the margin of error you’re willing to accept.
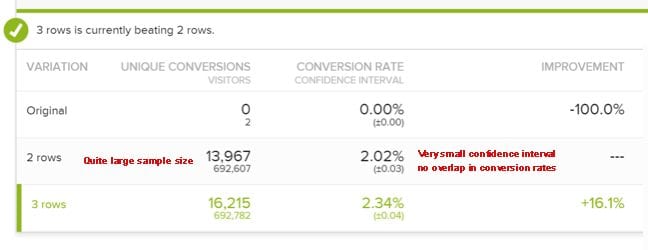
Here’s an example where there’s no overlap:
And here’s a new test (uncooked) with a large error margin:
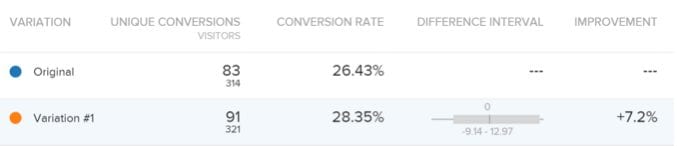
Notice how the difference interval is between -9.14% and +12.97%.
The first variation (as shown by the 1st image above) has little overlapping in its conversion rate range over the second variation (as shown by the 2nd image above) which has a significant overlapping in its conversion rate range and hence you can be more confident in picking the right winner & minimize the chances of a false positive or a false negative.
This one of the main reasons why people don’t get their target lift at the end of a test because its a prediction of the range of the lift and the median value is what people focus on, not the sample size.
Considering the confidence interval of your median value will help you see the actual range of the conversion rate. If the lower end of the conversion rate range is above your targeted value, then congrats!
Conclusion
Most marketing guys are not good in A/B testing stats.
It’s better not to be ignorant in such cases.
Stopping A/B testing early is one of the common rookie mistakes.
So when to stop a test? After these 4 conditions have been met:
- Calculate the needed sample size ahead of time and make sure to at least have that many people in your experiment.
- Make sure you have enough representativeness in your sample, run it full weeks at a time, at least 2 business cycles.
- Very small confidence intervals resulting in no overlaps on the conversion rates.
- Statistical significance should be looked upon once the above conditions are met.
If you need more successful tests then you should get yourself up to date with all the conversion optimization techniques.